
The Architecture of This Site
Mar 11, 2024
11 min read
views

Introduction
“There are no solutions, only tradeoffs.”
This post outlines the architecture of this site and some of the tradeoffs that were made along the way to building it. That is, on the way to over-engineering a simple blog.
Roughly speaking, however, this site uses the MERN stack (Mongo, Express, React, Node). It runs as a small group of microservices and serverless functions in DigitalOcean. The engineering goals here were the following:
- To have excellent front end performance
- To adopt engineering best practices and adhere to them sometimes too strictly
- To learn new things
- To keep cloud costs predictably low
Simplified Visual Overview
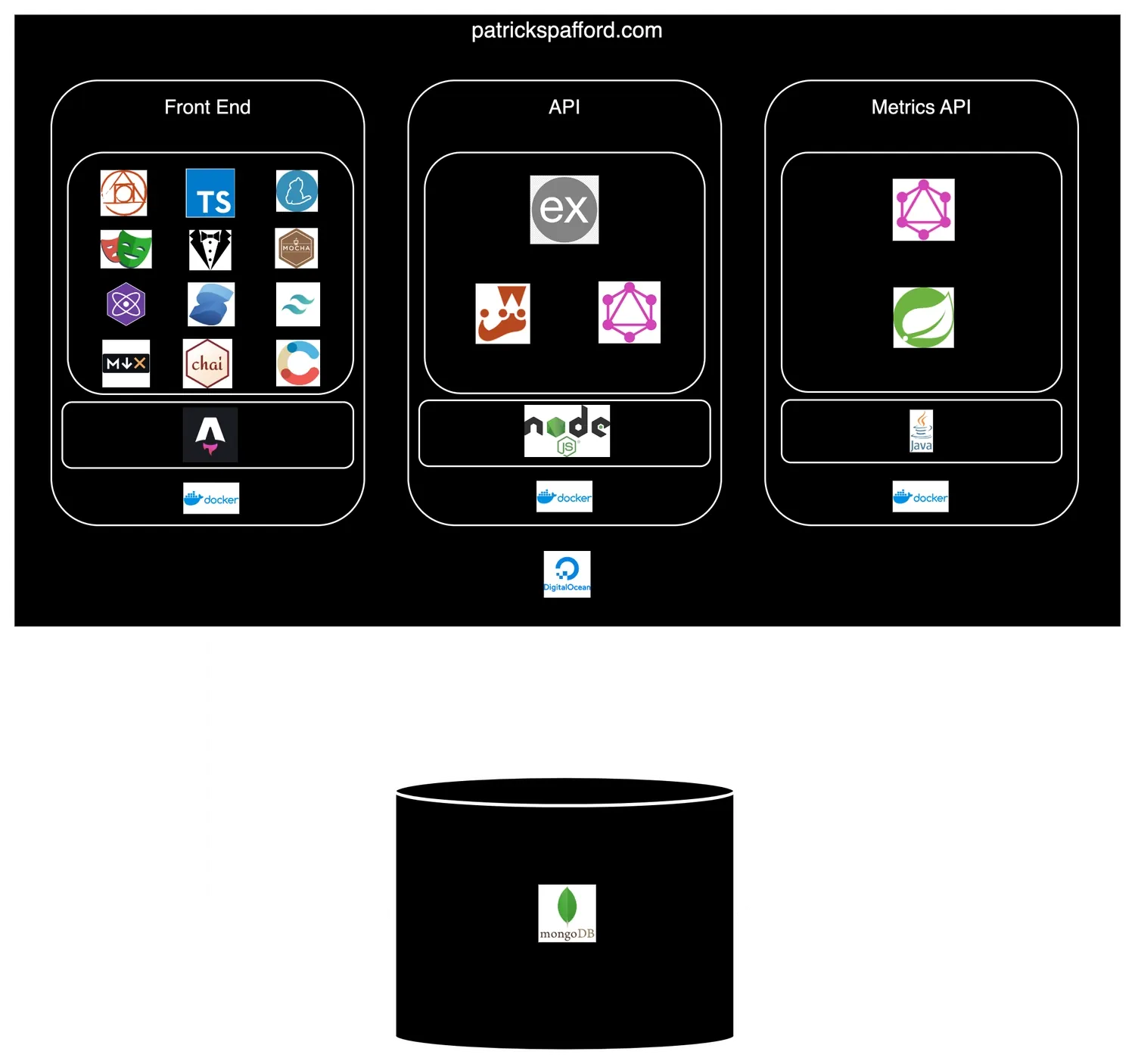
Front End
Not exhaustive, of course.
Stack
| Name | Utility |
|---|---|
| Astro | Web meta-framework |
| Preact | For complex or interactive pieces of the UI |
| TypeScript | General purpose programming language (e.g. for Preact components) |
| MDX JS | For authoring rich posts in Markdown |
| Tailwind CSS | For styling |
| DigitalOcean App | For deploying the site |
| Contentful | To support guest posts |
| Solid.js | For complex pieces of the UI where rerendering needs to be kept to a minimum |
| Docker | For containerization |
| Mocha | For unit testing |
| Chai | For unit test assertions |
| Stylelint | For enforcing best practices with bespoke CSS |
| Playwright | For UI tests that run in various browsers |
| Yarn | For managing packages and the monorepo |
| PostCSS | Part of using the Astro Tailwind integration |
Why I Chose Astro
I chose Astro as the meta-framework for this site for a few reasons:
- Because of its “islands of hydration” internal architecture, it’s easier to maximize Lighthouse performance.
- The framework is extensible with Astro integrations. Most notably, you can use multiple UI frameworks (Vue, React, Preact, Solid.js, Svelte) in the same project.
- It has an integration for writing posts in Markdown.
- It allows you to specify which routes to pre-render and which routes to render dynamically (SSR).
- It is component-driven, so the static elements on the page (the
.astrocomponents) can be easily composed into complete pages in the same way that you would with a UI framework.
The major tradeoff here is that Astro helps you build multi-page applications (MPAs), not single page applications (SPAs). You can load SPAs on top of Astro, but fundamentally, Astro is an MPA meta-framework. That means that the routing is not done client-side like with a React app. In a React application, app state is persisted. When you click a link to another page on that React web app, React prevents a full page refresh and uses JavaScript to render the page. Yes, React still has to take the time to render the page and mount elements to the DOM, but it does not have to make another trip across the nextwork boundary to fetch that page. This was paid for up front when you loaded the SPA.
MPAs tend to have a slightly worse experience for the user than SPAs, that is, after the initial app / page load. Because of this, a couple of notable things on this site were more difficult: (1) preventing a flash of unstyled content (FOUC) with dark mode on refresh or page transition and (2) making the experience of navigating the site a pleasant one. Astro’s page transitions and being deliberate about prefetching links mitigates the latter concern.
I could have chosen Next.js, Remix, Hugo, Gatsby or any number of web frameworks here, but ultimately, I chose Astro because it was the best fit for my use case: a high-performance content site with some interactive parts here and there. In 2021, patrickspafford.com was a Gatsby site. The reason I moved away from it was primarily performance-related. While I’m not claiming that a good score isn’t possible with Gatsby, it was easier with Astro.
API
Stack
| Name | Utility |
|---|---|
| Node.js | Runtime |
| Express.js | API Framework |
| MongoDB | NoSQL Database |
| Jest | Unit testing |
| GraphQL | As an alternative way of fetching data |
| Docker | Containerization |
| DigitalOcean App | For deploying the API |
| GitHub Issues API | For tracking job offers |
Description
The API is a RESTful Express app. It tracks blog post views and handles job offer submissions. It uses MongoDB as a database since relational integrity is not a big concern. The blost post view tracker is relatively straightforward and creates a Mongo document for each post. The job offer submission function, however, does something a little different and should arguably be a separate microservice. This is because the job offer route does not interact with the Mongo database. It instead creates an issue on my GitHub repo (which is private at the time of writing). I once tried sending email and SMS notifications with Twilio, but there wasn’t enough bang for buck here.
As far as performance, the API is enhanced with an in-memory cache to speed GET requests up a bit. For learning’s sake, there’s a GraphQL route at /api/graphql, but it allows queries only (no mutations).
The API could potentially be enhanced with an production-grade in-memory database like Redis, but I chose an NPM package for in-memory caching instead. Better than managing more cloud infrastructure for little performance gain on something where performance is not a huge concern.
One note on quality assurance: Any change that is made to the API is tested at https://dev.patrickspafford.com/api before it goes into production. The same is also true for the front end. The dev environment does not always exist; I spin it up as needed to validate changes. I explain this in-depth in the “Change Process” section.
Metrics API
Stack
| Name | Utility |
|---|---|
| Java | Programming language & runtime |
| Spring | API framework |
| GraphQL | As an alternative way to fetch data |
| Docker | Containerization |
| Gradle | Build system |
| MongoDB | NoSQL database |
Description
The API at /metrics-api is a RESTful Java application. The reason it’s not also an Express app is purely for the sake of learning. That said, this microservice is for collecting metrics on the blog’s Express API (/api). While it’s decoupled from that, it does use the same MongoDB cluster in DigitalOcean in order to minimize cost. It stores data in a separate database within that cluster.
The metrics that get collected by this microservice have a lifecycle. By creating an index on MongoDB documents based on their timestamp, MongoDB automatically discards old metrics. This is helpful so that the database doesn’t grow indefinitely and eat up unnecessary storage.
One tradeoff with running this as a separate microservice is cost. Running this API serverlessly would be another option, but Java isn’t a commonly-supported runtime on serverless platforms and part of the goal here was to simply develop something in Java.
Mahomes Mountain API
Stack
| Name | Utility |
|---|---|
| Python | Programming language and runtime |
| DigitalOcean Functions | Cloud service for running “serverless” functions |
| MongoDB | NoSQL database |
Description
There is a serverless Python API that is totally separate from the patrickspafford.com DigitalOcean app, but I include it here because it powers the Mahomes Mountain demo. It, too, has a distinct database in the MongoDB cluster and runs as a couple of serverless functions: 1 endpoint for QBs and 1 for seasons. The site only invokes this API on each build. This keeps things snappy on the front end and keeps costs predictably low (usually free). I also don’t need to worry as much about security since it’s an internal-only API.
The tradeoff here with running it serverlessly at build-time is that making updates to a season or adding new visualizations is a 2 step process:
- Update the data.
- Redeploy the front end.
Infrastructure
With rare exceptions, the site’s infrastructure is managed via Terraform.
It is separated into 3 projects: development, production, and substrate.
| Terraform Project | Description | Strategy | Git Branch |
|---|---|---|---|
| Development | Manages infrastructure for testing changes before they go into production. A near copy of production hosted at dev.patrickspafford.com | Continuous Deployment | dev |
| Production | Manages infrastructure for things that are public and go under the patrickspafford.com domain | Continuous Delivery | production |
| Substrate | Manages infrastructure that undergirds all environments (dev, prod). E.g., the MongoDB cluster | Continuous Delivery | production |
The development and production environment mirror a branching convention in GitHub. There are dev and production branches, but no substrate branch since changes to the substrate infra would impact prod. Whenever a pull request is opened, a plan is automatically triggered in Terraform Cloud and the status of that plan is posted to the PR as a merge check.
When a commit is made to the dev branch, it automatically replans and applies that plan without any human intervention. This is because the testing environment is, in principle, independent of production. So the risk of auto-applying plans is low. Hence, “continuous deployment” is at work here.
When a commit is made to the production branch, it replans on both the substrate and the production TF projects and waits for manual confirmation before applying those changes. The appetite for risk is lower here, so in short, both substrate and production employ “continuous delivery”.
Change Process
Sequence
There is a process for developing and releasing changes to this site. The following steps pertain specifically to the front end, since the front end is the closest adherent to engineering best practices.
- Check out a new branch off of
devaccording to the branching convention<change type>/<github issue id>/<short description>. - Develop the change.
- Write unit tests.
- Write Playwright tests.
- Test the change manually locally.
- Commit to the feature branch.
- The branching convention and Angular-style commit message convention are enforced at this point using Husky.
- Push the feature branch remotely.
- Unit tests run locally. If they fail, it will cancel the Git push.
- Open a PR from the feature branch to
dev. The following merge checks run via GitHub Actions:- Unit tests
- Bundle size tests
- Integration tests in multiple browsers with Playwright
- A plan runs in Terraform Cloud
- The Docker image for the front end is built, but not published anywhere. It is ephemeral.
- If all checks pass, the PR can be merged.
- Since a commit has been made to
dev, the Terraform plan for thedevbranch will automatically apply in the branch-specific Terraform project. - If there is a change to the version in the front end’s
package.json, GitHub Actions builds a new Docker image and publishes it to a private container registry in DigitalOcean. Dev and production each get their own container repository within this shared registry.- The publish process will fail if there already exists an image with that version.
- If all goes well here, a release commit will be made to deploy the new version of the front end. We deploy by changing a JSON manifest file in the infra folder of the monorepo and pushing that change upstream.
- The manifest file is rather simple. It maps a component of the site to a Docker image version. Each environment gets its own map within this file.
- Terraform Cloud will pick up that a new commit has been made to
devand deploy the Docker image, pulling from the private container registry. - The feature is then tested at
dev.patrickspafford.commanually. - If something goes wrong, no big deal. It’s a non-production environment.
- If all is well and the feature works as expected, a PR will be opened from
devtoproductionin GitHub. - The same merge checks run as before but with 1 addition: GitHub Actions runs a Google Lighthouse test on
dev.patrickspafford.comand reports the scores. - If all merge checks pass, the PR should be manually merged. The process is very similar to before when it comes to Docker images and the manifest. The exception is the fact that pushing to the
productionbranch doesn’t trigger an auto-apply. It only does a plan and waits for manual confirmation. - At this point, I would confirm the changes in Terraform Cloud. It will deploy the version specified in the manifest file on the
productionbranch. - Voila! The app is now here on the main site and is validated again manually just to be safe. Sometimes, I will send a link to a family member and ask them to check it out. (Hey, can’t hurt)
- Ideally though, a “canary” would eventually monitor the main site. This automated test would monitor the functionality of the site and cut a GitHub issue when something goes awry. That being said, the DigitalOcean app already has basic health checks (e.g., domain misconfiguration, checking the HTTP status code of the home page) and I’ll get an email about that.
- If something did go wrong at any point with
production, I would simply roll back the change by switching the version of the site in the manifest file and confirming that change in Terraform Cloud. The previous Docker image still lives in the container registry, so the rollback is predictable and safe. No need to scramble for a hotfix.
Tradeoffs
| Decision | Pros | Cons |
|---|---|---|
| Running Astro as a service and not as a static site | Predictable rollbacks, decoupling artifact generation from deployments, SSR | More expensive to run as a DigitalOcean service than as a static site |
| “Continuous Delivery” for production infrastructure | Changes to production have to be more intentional | Inconsistent with dev environment strategy, source code is not as good an indicator of what is live |
| A branch for each environment | Easy to check the state of each environment, intuitive mental model | Hard to manage if there are many places to deploy (e.g., deploy production across 15 regions) |
Conclusion
At a high-level, that’s how this site is structured. Hopefully you can also see why this particular architecture and tech stack aligns with the engineering goals that I set out to reach. If you want to build something similar, let me know!